
(Editor’s note 7/8/2024: This post has been edited and updated since it first posted in 2019.) This new ancestry breakdown in Central and South Asia is currently available to customers on the latest version of our genotyping platform who are signed up for our Beta Program. This update significantly advances Asian DNA testing, offering more detailed and accurate results.
South Asian people represent around a quarter of the world’s population but are severely underrepresented in global genetic studies. This makes it difficult for companies like 23andMe to build granular genetic ancestry prediction models for their South Asian customers. However, thanks to ongoing feedback from 23andMe customers with South Asian ancestry and outreach efforts such as our Global Genetics Project, we are now testing an extensive update to our Ancestry Composition feature that dramatically improves results for customers with Central and South Asian ancestry.
If you have genetic ancestry from Afghanistan, Pakistan, India, Bangladesh, Sri Lanka, or Nepal, your 23andMe Ancestry Composition results may have looked something like this:
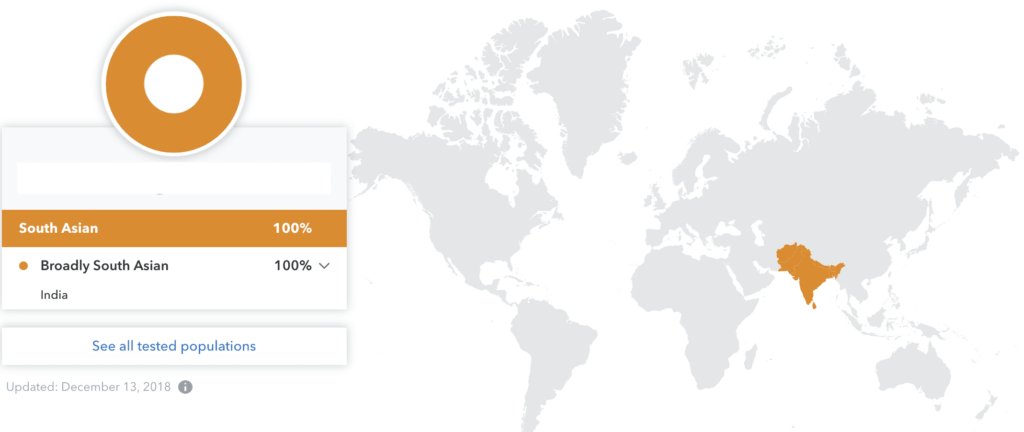
But now, 23andMe’s updated Ancestry Composition report (currently in beta testing with customers) breaks down Central & South Asia into seven populations:
- Central Asian (Afghan, Kazakh, Kyrgyz, Pashtun, Pakistani from the Federally Administered Tribal Areas, Tajik, Uzbek, Turkmen)
- Bangladeshi & Northeast Indian (Assamese, Bangladeshi)
- Central & Southern Indian (name of group TBD)
- Gujarati Patel
- Kannadiga, Tamil, Telugu & Sri Lankan
- Malayali
- North Indian & South Pakistani (Bihari, Burusho, Chhattisgarhi, Goan, Gujarati, Haryanvi, Kashmiri, Madhya Pradeshi, Maharashtrian, Odia, Punjabi, Rajasthani, Sindhi, Uttarakhandi, Uttar Pradeshi).
Here is a sample report with updated results. This individual has ancestry from three of the seven populations highlighted on the map.
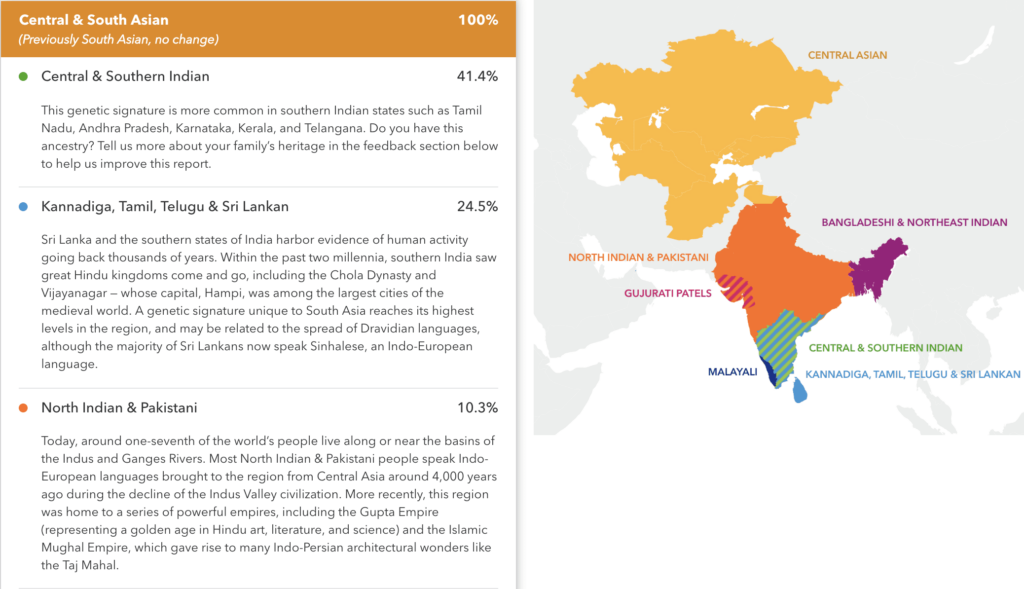
How did we identify these new genetic regions in Central & South Asia?
The first step toward increasing the granularity of Ancestry Composition in Central & South Asia and enhancing the precision of our Asian ancestry test was to build a reference dataset from populations within the regions.
We started with publicly available datasets, including the 1000 Genomes Project (Bangladeshis, Gujaratis, Punjabis, Tamils, and Telugu-speakers) and the Human Genome Diversity Project (Burusho and Sindhi). Next, we added research-consented customers who reported that all four of their grandparents were from a country in Central or South Asia. This effort significantly enhances the accuracy of Asian DNA testing by expanding the reference panel used in Ancestry Composition. Previously, the panel included 1,022 South Asian individuals, but this update more than doubles the size of the panel to 2,696, of which 2,164 are 23andMe customers.
After assembling this group of Central and South Asian individuals, we used genetic clustering techniques to identify distinguishable populations. These techniques allow us to generate two-dimensional plots wherein each individual is represented by a single point. Points corresponding to individuals who are genetically similar to one another generally appear close to one another in these plots, forming clouds, or “clusters,” of points.
To figure out which individuals defined each cluster, we colored each data point by the locations, ethnicities, or languages of their ancestors.
Sometimes, a cluster’s label is pretty easy to figure out: for example, here’s an older scatter plot of our European reference individuals (you can find the whole plot with a legend in our Ancestry Composition Guide), in which we observed that Sardinians form a distinct genetic cluster. 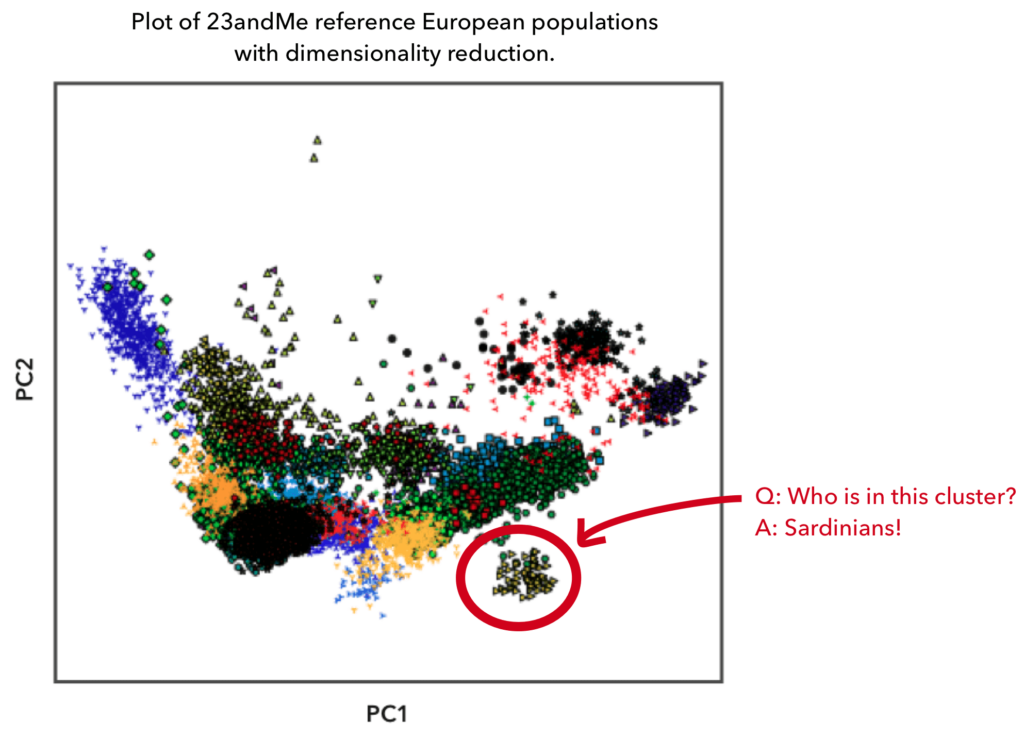
What about Population Clusters in Central & South Asia?
In a recent study, the authors of a group at McGill University in Montreal identified distinct genetic clusters in South Asia.
In this figure (modified from reference 1), we have removed populations from other world regions for clarity. Note that there are two distinct clusters composed of people who say their ancestors were born in Gujarat. Who are these Gujaratis? And what makes them different from other Gujaratis?
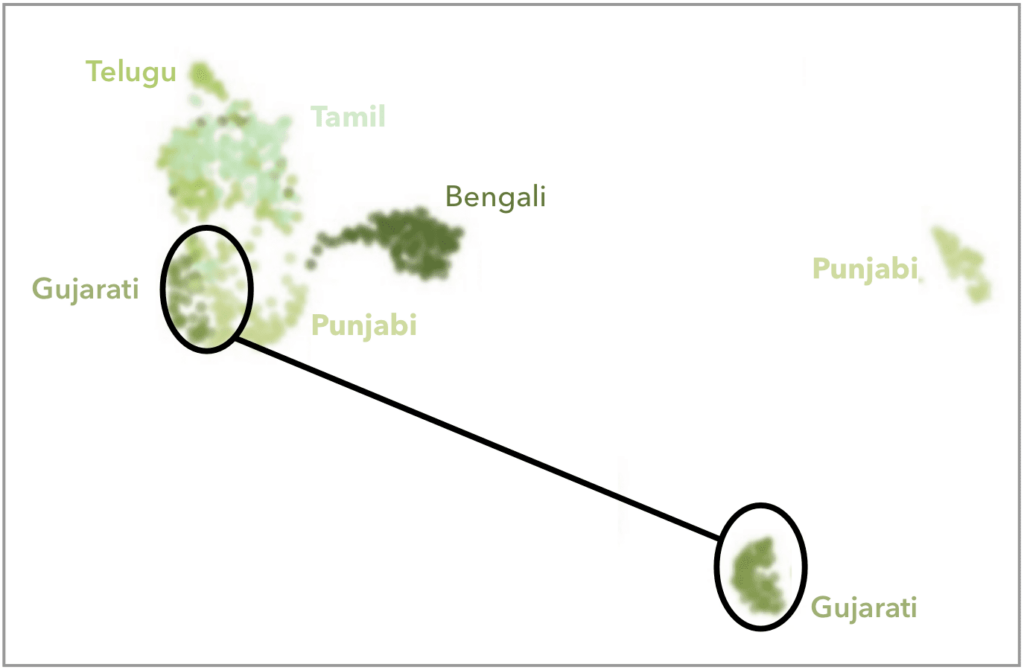
23andMe also identified this distinct group of Gujaratis. Through further analyses, surveys, and confirmation from Beta testers, we determined that most individuals have the last name Patel. The Patels of Gujarat are a large community from western India that primarily descends from agricultural and merchant classes. (The name “Patel” is derived from the name “Patidar,” which means “landowner.”)
One reason this group might be so different from other populations in Gujarat is that a distinctive genetic heritage developed over the centuries as Patels favored marriage within their community. The practice of marrying within a small cultural, religious, or otherwise closely-knit community is called “endogamy,” and distinct genetic populations that form as the result of endogamy are found all around the world (including French Canadian, Armenian, and Ashkenazi Jewish populations among many others).
What else did we find?
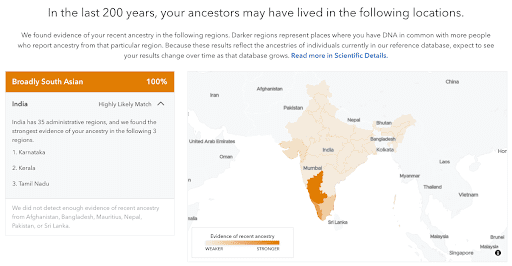
Another cluster we identified comprises people from Kerala—the southwestern-most state on the Indian mainland. These individuals were genetically distinguishable from the residents of neighboring states in southern India, like Tamil Nadu and Karnataka. Other groups, like “Central Asian,” “North Indian & Pakistani,” “Bangladeshi & Northeast Indian,” and “Kannadiga, Telugu, Tamil & Sri Lankan,” were more geographically broad. Still, individual customers may be able to see additional granularity in their Ancestry Detail Reports (see sample report, below, of a customer with known ancestry from Karnataka).
 Finally, there’s a group we’re calling “Central & Southern Indian.” We know they’re genetically distinct, and we have a hypothesis about what makes them distinct. Still, we need our customers’ help to learn more about how people with this genetic ancestry might identify. That’s why our Beta testers’ feedback is so important to us. Your feedback helps us identify solutions, enact them, and make 23andMe features even better for all customers.
Finally, there’s a group we’re calling “Central & Southern Indian.” We know they’re genetically distinct, and we have a hypothesis about what makes them distinct. Still, we need our customers’ help to learn more about how people with this genetic ancestry might identify. That’s why our Beta testers’ feedback is so important to us. Your feedback helps us identify solutions, enact them, and make 23andMe features even better for all customers.
It is important to remember that people with ancestry from regions where these populations overlap may see population mixtures in their results. For example, many people from Afghanistan have a combination of “Central Asian,” “North Indian & Pakistani,” and “Western Asian” DNA based on the reference populations chosen for this analysis.
We hope that some of these new genetic populations are now easier to interpret and that you learned something fun about genetic analysis along the way.
At the end of the day, identity is determined by many things, and each customer’s experience is unique when they explore their Ancestry Composition results. With this in mind, we invite you to share your thoughts with us, either through the feedback survey in the Central & South Asian Beta report, or by commenting on the forums.
Reference:
- Diaz-Papkovich A et al. (2018). “Revealing multi-scale population structure in large cohorts.” bioRxiv preprint. doi: https://doi.org/10.1101/423632.



