
Improved accuracy. Less uncertainty. Better science.
We like to call 23andMe’s Ancestry Composition a living analysis of your DNA that gets better and more granular over time as more people from different backgrounds become customers.
This fall, we’re upgrading to that analysis to improve accuracy and reduce the number of “unassigned” and non-specific ancestry assignments. But, some 23andMe users may see some pretty significant shifts in their results. For example, many should expect an increase in their most common ancestry proportion and a reduction in their broad ancestries. The end of this post includes a summary of some of the most common ways in which 23andMe users’ results will change.
In parallel with this 23andMe upgrade to the Ancestry Composition analysis, we’re updating our reference dataset for our recent ancestor locations feature, so you might see your recent ancestor locations and match strengths change as well.
This is all part of our ongoing efforts to improve our customer offerings. It’s worth looking back at what we’ve done since 2008 when we first started offering customers a breakdown of their ancestry.
A look back
A lot has happened in the past 12 years. Millions of individuals have joined 23andMe, and ongoing research efforts have helped us understand more about genetic diversity worldwide. 23andMe has also made great strides in improving the underlying algorithms and reference populations we use to deliver these results. In 2008, we divided ancestry into three main categories: African, European, and East Asian. Since then, we’ve offered a series of updates where we refined those original estimates into more and more granular results. Now, customers can discover if their DNA traces to more than 2,000 regions worldwide.
When we update the algorithms or the reference populations used to predict your ancestry, your results are expected to change. That’s why we call Ancestry Composition a living analysis of your DNA. Mostly, these changes should be minor and hopefully provide you with more detail about your ancestral origins. Like almost everything we do, these changes are based on science, and we want to be transparent about our actions. That’s why each time we make an update, we share it in our “Change Log,” which can be found at the bottom of the Scientific Details section of your Ancestry Composition report. If you want even more detail, you can look at our Ancestry Composition Guide, or for those with a science bent, check out our White Paper.
More about the most recent update to Ancestry Composition
Since 2014, 23andMe has added or expanded dozens of reference populations, but the core Ancestry Composition algorithm has remained almost completely unchanged. Until now.
In 2020, our R&D team developed a new approach that dramatically improves accuracy while reducing unassigned and nonspecific ancestry. This update is a significant part of our latest 23andMe upgrade.
To understand what’s changing, let’s first review the basics.
A simple, step-by-step guide to Ancestry Composition
Step 1: Assigning
First, in our Ancestry DNA update, we separate the customer’s genome data into small segments, similar to train boxcars. Each boxcar contains data for about 300 DNA markers, out of the total of over 650,000 markers we test on our genotyping chip. By dividing 650,000 by 300 DNA markers, we get approximately 2,000 boxcars.
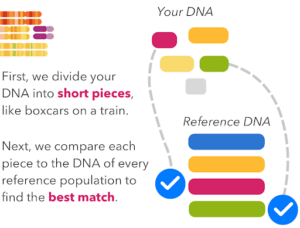
For each of those 2,000 DNA boxcars, the algorithm picks the most closely matching genetic population out of the 45 we currently have in many head-to-head match-ups.
But this first step is noisy and prone to error, especially if someone has ancestry, say, from two neighboring populations. If an assignment is made to each boxcar without considering the neighboring boxcars, then the algorithm is missing useful information about ancestry segments extending across several boxcars.
That’s where the next step comes in!
Step 2: Smoothing
In our Ancestry DNA update, the next step of the algorithm is called “smoothing” because it makes the results from the first step less noisy. In this step, we use information from neighboring DNA boxcars to make a more informed decision about the most likely ancestry of individual boxcars.
Let’s say a boxcar seems to match Sudanese ancestry, but many of the surrounding boxcars match Ethiopians with high confidence (Sudan and Ethiopia are neighboring countries). The smoother uses that information to adjust the prediction for that middle boxcar and assigns Ethiopian instead.
Or, say there’s a stretch of boxcars that don’t match Ethiopian or Sudanese with high confidence. Here, the smoother can “zoom out” to a broader population called “Northern East African,” at which point it will be highly confident in that assignment.


What Are DNA Markers?
DNA markers are specific sequences in the genome used to identify genetic differences between individuals or populations. These markers play a crucial role in genome data analysis by helping scientists match genetic data with reference populations accurately.
So, what’s special about this update to Ancestry Composition?
In our Ancestry DNA update, our R&D team realized that we could significantly improve the second step—smoothing—which would dramatically enhance the accuracy of people’s results.
Previously, the models used in the smoothing process were trained using the genomes of thousands of customers. (“Training” a model means setting its “dials” based on a dataset so that it can make the most accurate predictions.) These pre-trained models were then applied to each new customer’s genome. In practice, this step was prone to over-generalizing, which customers saw as results with higher levels of unassigned ancestry or non-specific ancestry, such as “Broadly Southern European.”
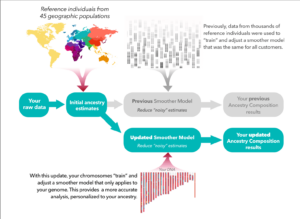
It was analogous to estimating an individual’s salary based on statewide salary data. But what if we could estimate that individual’s salary based on data from their specific zip code? So, the R&D team developed a new approach that trains a custom smoother model for each customer, avoiding the over-generalizations of the previous approach. This custom smoother model still reduces the noise across DNA boxcars and produces Ancestry Composition results that are, at the same time, more accurate and more specific.
How will customers’ results be affected by this update?
While customers with ancestry from certain parts of the world will be affected more by this update than others, everyone should see some adjustments to their Ancestry Composition.
We understand that changing results can be confusing, but Ancestry Composition is a living analysis, and this update reduces uncertainty and improves accuracy for most customers.
Here are some trends in how customers’ results are changing:
- Many customers, in particular customers with ancestry from Central & South America, could see a significant reduction in the amount of their unassigned ancestry.
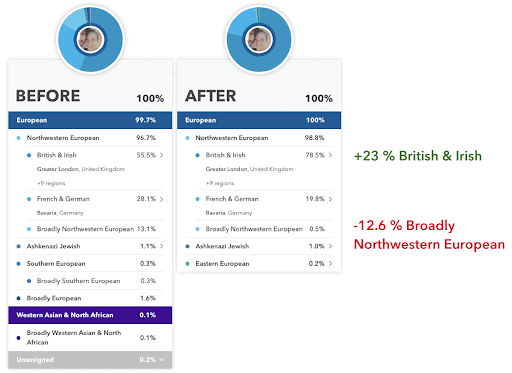
- Many customers could see a significant reduction in the number of their broad ancestry assignments, such as “Broadly Northwestern European.”
- In general, we should now be better able to confidently assign more of your most common ancestry. For example, if you have primarily British & Irish ancestry, you may see your British & Irish percentage increase with this update.
- Many customers will see a drop in the number of their trace ancestry assignments.
Ancestry-Specific Changes (general trends)
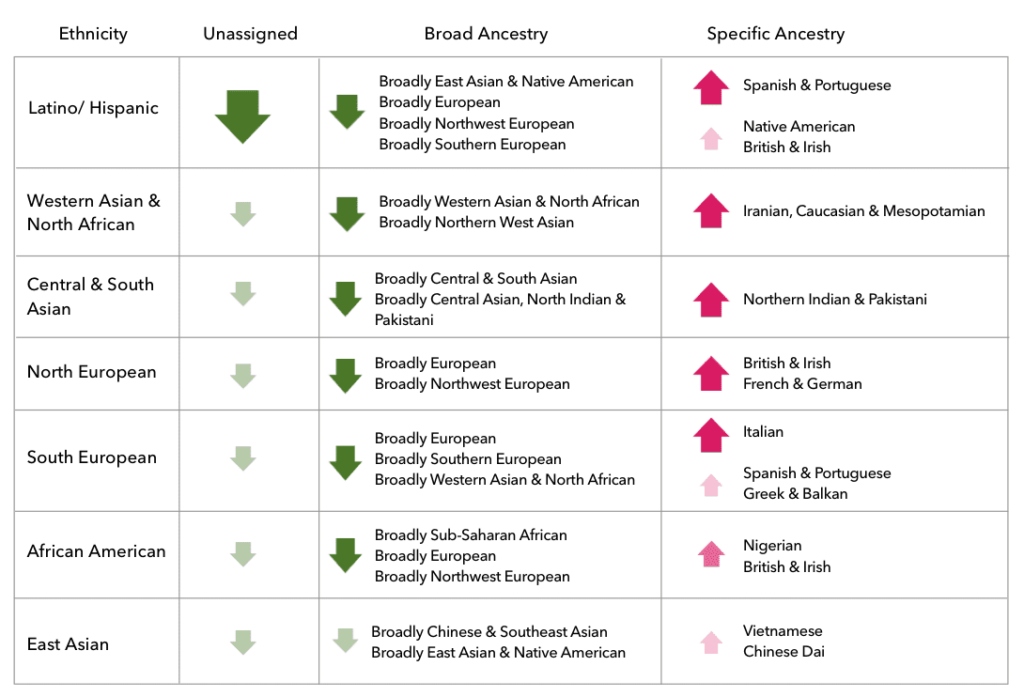
Keep in mind that these are general trends, and changes in your own results may be very different from the changes shown here.
Example customer changes:
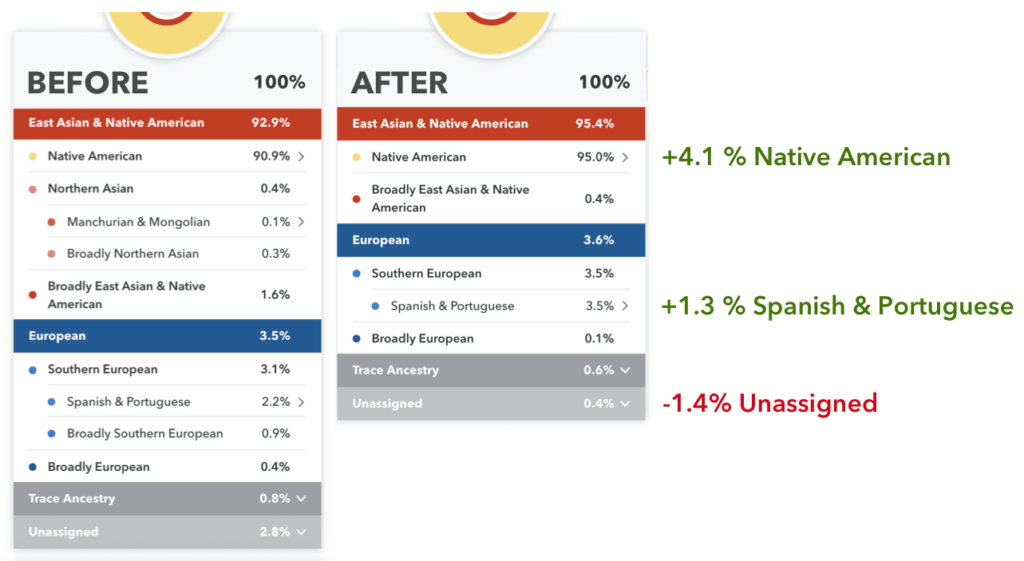
Visit your Ancestry Composition report to see your updated results.
This update is only available to customers on our genotyping platform’s most recent version (Version 5). You can check which version you are on near the bottom of the “Personal Information” section of your profile settings page.



