The genome of any two humans are almost identical.
 On average, for every 1,000 DNA bases about 999 of them are exactly the same between you and any other person on the planet. Over your entire 6 billion DNA base pair genome, however, that one difference in a thousand adds up to several millions of differences.
On average, for every 1,000 DNA bases about 999 of them are exactly the same between you and any other person on the planet. Over your entire 6 billion DNA base pair genome, however, that one difference in a thousand adds up to several millions of differences.
Two New Studies
In studies published by Science and Nature this week, scientists have taken their most detailed look yet at these genetic differences. In this blog post, we’ll take a brisk stroll through their findings.
Both studies are based on around 600,000 SNPs genotyped in individuals (i.e., people) from the Human Genome Diversity Panel(HGDP-CEPH). HGDP-CEPH is a remarkable scientific resource. It consists of immortalized cell lines from 1064 individuals in 51 populations scattered around the globe.
The idea guiding the creation of the panel was to take a wide-angle snapshot of human genetic diversity. This explains the presence in the panel of little-known populations like the Uygur, the Surui, and the Xibo, alongside more familiar populations like the Japanese, Palestinians, and French. This polyglot collection reposes at the Fondation Jean Dausset in Paris, as it has now for nearly a decade.
Genetic Diversity
The Science study peers closely into those one-per-thousand differences between people, asking: Of all the genetic diversity seen in the panel, how much is found between people from the same population, how much between people from different populations in the same geographic region, and how much between people from different geographic regions?
For example, if there were no within-population diversity that would mean that all Russians are genetically identical, all Surui are identical, and so on, and therefore that all human genetic diversity must exist at the population and regional levels.
The paper finds nearly the opposite. About 90% of human diversity exists within populations, with most of the remaining 10% existing between geographic regions. This strongly confirms a decades-old result in human genetics: of those very few DNA bases which differ between people, a small minority of these differ between peoples.
Even so, 10% of several million differences is still a lot of differences between populations. Both studies zoom in on these differences, mustering some mathematical machinery called Bayesian cluster analysis, and ask: how easy is it to guess someone’s ethnicity based on their genotype?
Finding the Differences
The answer the two papers find is that it’s pretty easy, at least on the regional scale. The following figure, drawn from earlier work done by many of the same researchers that was published in the open-access journal PLoS Genetics in 2005, illustrates the results of the analysis; these are qualitatively the same as the results shown in the fancifully-priced Science and Nature figures.
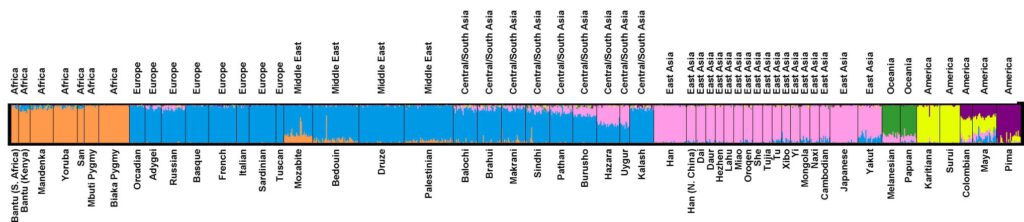
Each one of the (very) thin vertical lines in the figure represents a person, and the colors comprising each line correspond to the inferred proportion of ancestry from each of seven world regions. The key here is that the cluster analysis has no notion of a region or a population. It is simply told to divide up the genetic diversity into seven clusters (or six or eight — the results don’t change much), and then to guess which cluster or clusters each individual belongs to. The ethnic and regional labels are only applied once the analysis is through and, as is plain, the agreement between the donor-supplied ethnic label and the assignment is quite strong.
The papers go much further than we’ve seen here, looking into the history of human migration and exploring what happens when you use DNA insertions and deletions instead of SNPs to ask the same questions.
It’s worth noting that 23andMe is proud to have cosponsored the genotyping of the HGDP-CEPH that was conducted by the authors of the Science paper. The genotypes are available, gratis, at the CEPH website. We downloaded them ourselves, and now our customers can compare themselves to these very same populations using our Global Similarity feature.