
By Adam Auton, 23andMe Vice President, Human Genetics
For scientists at 23andMe, the recent announcement of taking our first wholly-owned cancer drug into a clinical trial is beyond exciting. This is a huge milestone for the company and for our Therapeutics group.
As a scientist and vice president for human genetics at 23andMe, I would love for more people to understand how important this is; not just for us at 23andMe, but also as a demonstration of how genetic research is transforming drug discovery.
So, I’m writing this post to explain how our unique database shapes our approach to drug target discovery. The intent is to share more about how we use both genetic information and non-genetic information together in the largest database of its kind. We are generating insights backed by human genetics at an unprecedented scale so that more people can benefit from what we learn about the human genome.
The two things to know is that at 23andMe, it all begins with human genetics, but it doesn’t end there.
But before diving into that, let’s take a detour using a real-world example to explain a bit about 23andMe’s unique research model and how it sets us apart.
The 23andMe COVID-19 Study
23andMe isn’t developing vaccines or therapies for COVID-19, so what does that have to do with this topic? Put simply, what we were able to do as scientists studying COVID-19 is a beautiful illustration of the power of our research model. Let me explain.
Early in the pandemic, the scientists at 23andMe, like scientists around the world, asked ourselves, “what can we do to help?”
23andMe has a very, very large database of re-contactable customers who have consented to participate in our research. That gives us the power to study all manner of diseases, including COVID-19.
We were curious whether there was something we could learn about the disease that could reveal more about its biological mechanisms and offer insights about potential ways to treat it. Specifically, we wanted to understand why some people get very sick with COVID-19, whereas others experience an asymptomatic infection. Why is this? Could genetics play a role?
We set up our COVID-19 Study and asked our research participants questions about their experience with the virus. In a matter of a few months, we had more than 1.2 million people participating in our study and we were able to generate a host of findings.
We found that blood type plays a role in the susceptibility to the virus and a locus on chromosome 3 appears to influence severity in symptoms among those who get it. And we found genetic associations with the loss of smell and taste among those with the virus.
Additionally, we investigated differences in vaccine reactions among people. We also have some of the largest cohorts of underrepresented populations, which allowed us to discern some of the different impacts the virus has had on people of different ethnicities. And we were able to share these findings with the scientific community, our customers, and the public at large as soon as we made them.
This is a great example of science in action. Recruiting and surveying large numbers of individuals regarding their experiences with a specific disease would usually take years. In this case, we were able to go from a scientific idea to a collection of results in a matter of weeks or months.
That’s the power of what we can do with our large-scale research platform that includes millions of people from diverse backgrounds who have consented to participate in research.
This relates to drug discovery in that it demonstrates the power of our research engine to discern important and relevant genetic associations quickly. But, of course, there are a number of steps and a lot more work that needs to happen after making those initial findings.

23andMe Therapeutics
Traditional drug discovery and development is incredibly inefficient and expensive. Developing a drug is difficult. On average, it can cost about $1 billion according to some estimates and can take more than a decade. And the failure rate for new drug development is more than 90 percent.
But suppose you start that process with evidence that a naturally occurring genetic variant within your target gene is associated with a particular disease. Studies have shown that the chances of successfully developing a drug against that gene are significantly increased, perhaps by a factor of two. Given this type of evidence, you can focus on targets that have the most promise for success and thereby accelerate the pace of developing a drug. In an industry where just one in ten drugs makes it to patients, the potential impact on transforming this expensive and time-consuming process is enormous.
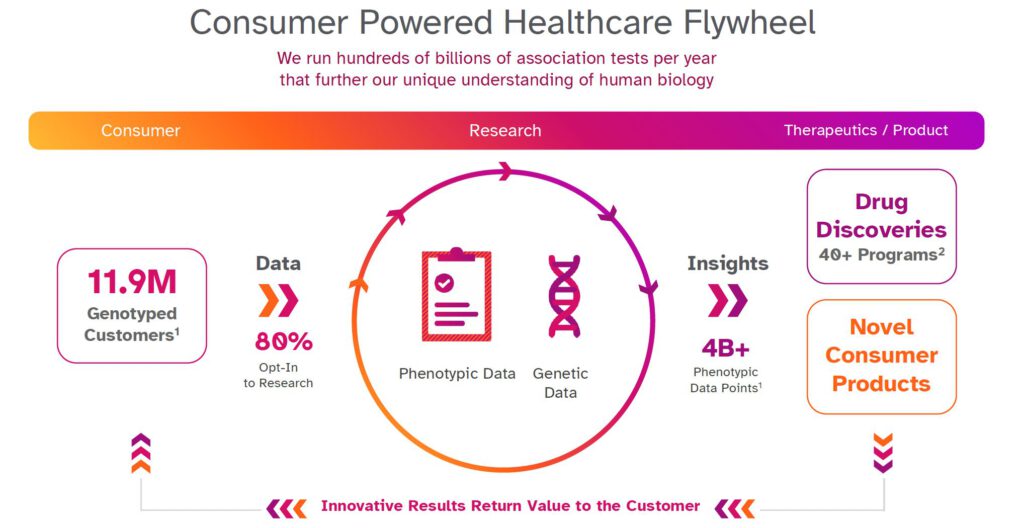
To find genetic associations relevant to targets, large datasets are important. As approximately 80% of 23andMe customers consent to participate in research, 23andMe has a large enough database to identify many genetic associations across thousands of diseases. In addition, people who consent to participate in our research can remain engaged, allowing our scientists to ask additional questions over time. This can, for instance, allow us to study the progression of different health conditions. Or, if our scientists are interested in better understanding a specific disease condition, we can go back and re-contact people to ask for more detail with regard to that condition, which can further help us understand how genetic variants are causing that specific disease condition.
All this data helps us improve the kind of information we can give back to customers, but it also powers new genetic insights, and over time we hope it will lead to the development of new therapies for people who need them most.
There really isn’t anything like it right now.
Drug Discovery
Our research data covers more than 1,000 different conditions.
This gives our scientists a unique opportunity to think about how genetics can reshape the translational science needed to move a potential target into the clinic.
Along with using genetic associations to discover new drug targets, we can also use genetics to understand the best path for a target into the clinic. Specifically, we might see a given target has genetic associations with multiple diseases, and we can use that information to decide where the target might be most beneficial for patients. This information might also allow us to see if a potential drug target is more likely to have serious side effects, in which case we could decide to move on from that target.
Combining the genetic data with multiple types of phenotypic data gives us a much deeper understanding of each specific gene and the underlying biology, allowing us to really focus our efforts on the targets with the highest chances of successfully becoming a drug.
Of course, having a genetic association is still a very long way from having a drug! There is a tremendous amount of work to do, and a lot of questions to answer. Even if we find an association, is it in or regulating a gene that we suspect plays a role in the biological mechanism of that disease? Are there experiments we can do to confirm our suspicions? Can the gene in question actually be drugged? Are other groups already working on this gene? What is the unmet medical need in this disease, and do we think drugging this gene would be better than the existing standard of care? We need to answer all of these questions (and many, many more), but by starting with what we believe is the greatest genetic database in the world, we hope that we are able to bring the best opportunities forward in order to help patients in need as quickly as possible.
My Background
I came to 23andMe about seven years ago, just as we formed the Therapeutics division. Previously I was an Assistant Professor of Genetics at Albert Einstein College of Medicine in New York City, where I worked on large-scale genetic analyses looking to understand the genetic underpinnings of human disease.
When I joined 23andMe, the database was much smaller, but it was clear that the potential was there. Since then, 23andMe has grown such that instead of seeing handfuls of genetic associations for different diseases, we are now seeing many thousands. Seeing this growth has been tremendously exciting.
This enormous database has allowed us to start more than 40 programs — many of which in collaboration with GSK — to develop targets to potentially treat conditions in oncology, immunology, respiratory and cardiometabolic disease.
What is game-changing about what 23andMe is doing is that we can make novel insights that simply aren’t available anywhere else. It is rewarding to see one of those insights lead to the development of a drug in a phase 1 clinical trial.

Adam Auton is the Vice President of Human Genetics at 23andMe and is responsible for computational approaches to target discovery via statistical genetics and computational biology. Before joining 23andMe, Adam was an assistant professor at Albert Einstein College of Medicine, where his group developed algorithmic approaches for using large-scale genomic data to understand human population genetics. Adam earned his DPhil in statistics from Oxford University, before completing his post-doctoral training at the Wellcome Trust Centre for Human Genetics at Oxford, and Cornell University.


